python爬虫实践之爬取hao123音乐音乐导航
本文共 907 字,大约阅读时间需要 3 分钟。
目录
概述
爬取hao123上的所有音乐导航链接
准备
所需模块
- re模块
- requests模块
涉及知识点
- python基础
- requests模块基础
- re模块基础
运行效果
控制台打印:

完成爬虫
1. 分析网页
打开音乐导航,按F12分析网页
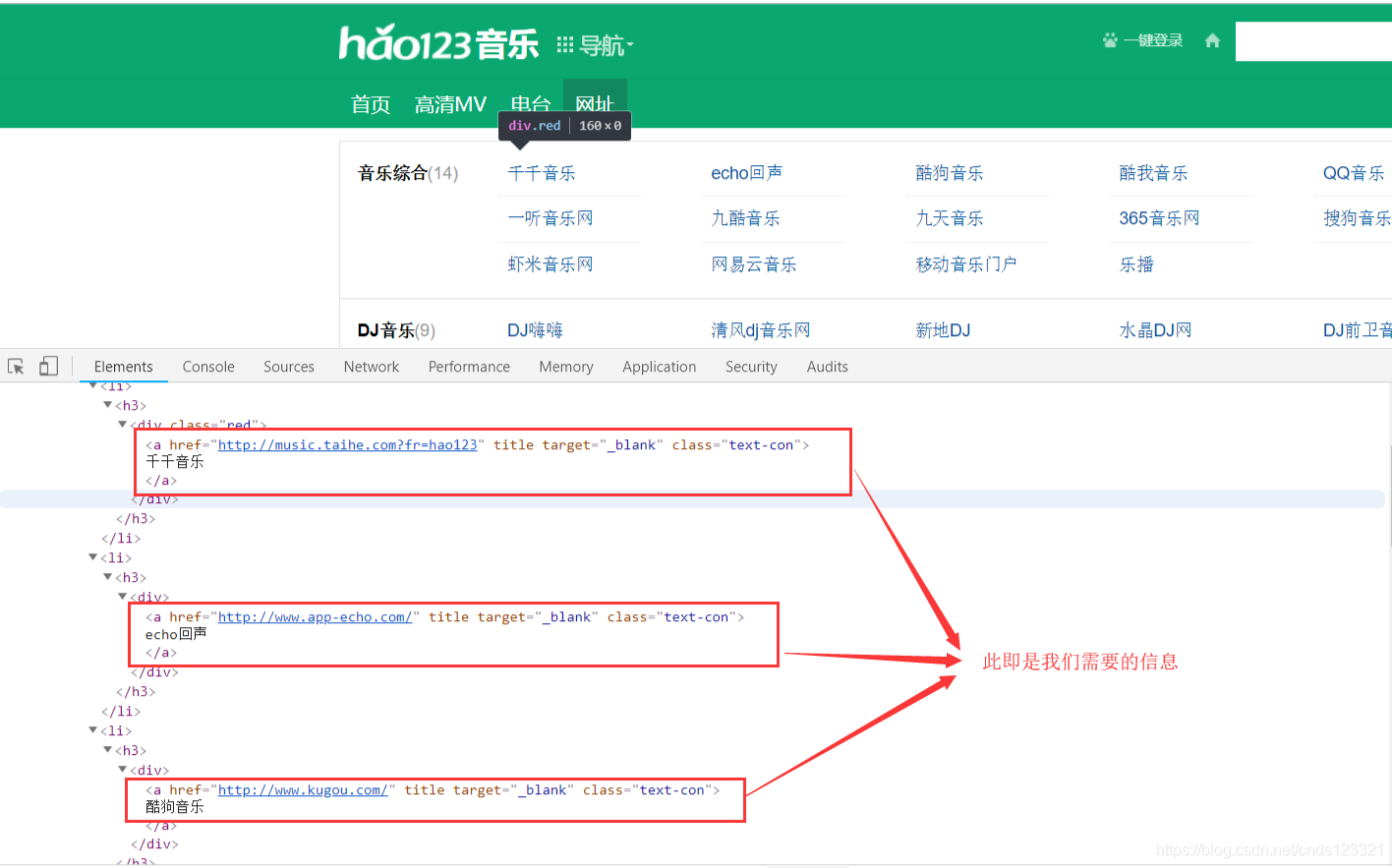
因此可以使用URL:请求该网页的HTML源代码进行数据获取。
2. 爬虫代码
import reimport requests# 音乐导航网址:http://www.hao123.com/music/wangzhi# 请求头header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"}# 请求的URLurl = "http://www.hao123.com/music/wangzhi"# 发送请求,获取响应response = requests.get(url, headers=header).text# 正则表达式:获取音乐导航链接URLpat_music_url = r''# 正则表达式:获取音乐导航名字pat_music_name = r'[\s\s]*?(.*?)[\s\s]*?'# 音乐导航URL列表music_url_list = re.findall(pat_music_url, response.strip())# 音乐导航名字列表music_name_list = re.findall(pat_music_name, response)# 循环遍历if len(music_url_list) == len(music_name_list): for i in range(0, len(music_url_list)): print(music_name_list[i], ":", music_url_list[i]) 运行代码结果如上所示,主要的难点就是使用正则表达式提取数据。
转载地址:http://vqzx.baihongyu.com/
你可能感兴趣的文章
MySQL-数据目录
查看>>
MySQL-数据页的结构
查看>>
MySQL-架构篇
查看>>
MySQL-索引的分类(聚簇索引、二级索引、联合索引)
查看>>
Mysql-触发器及创建触发器失败原因
查看>>
MySQL-连接
查看>>
mysql-递归查询(二)
查看>>
MySQL5.1安装
查看>>
mysql5.5和5.6版本间的坑
查看>>
mysql5.5最简安装教程
查看>>
mysql5.6 TIME,DATETIME,TIMESTAMP
查看>>
mysql5.6.21重置数据库的root密码
查看>>
Mysql5.6主从复制-基于binlog
查看>>
MySQL5.6忘记root密码(win平台)
查看>>
MySQL5.6的Linux安装shell脚本之二进制安装(一)
查看>>
MySQL5.6的zip包安装教程
查看>>
mysql5.7 for windows_MySQL 5.7 for Windows 解压缩版配置安装
查看>>
Webpack 基本环境搭建
查看>>
mysql5.7 安装版 表不能输入汉字解决方案
查看>>
MySQL5.7.18主从复制搭建(一主一从)
查看>>